Kafka Adapter for OIC
The Kafka adapter for Oracle Integration Cloud came out earlier this month, and it was one of the most anticipated releases.

So what is Kafka? You can find all about it on https://kafka.apache.org/, but in a nutshell:
Apache
Kafka is a distributed streaming platform with three main key
capabilities:
- Publish and subscribe to streams of records.
- Store streams of records in a fault-tolerant durable way.
- Process streams of records as they occur.
Kafka is run as a cluster on one or more servers that can span multiple data centres. The Kafka cluster stores streams of records in categories called topics, and each record consists of a key, a value, and a timestamp.
Kafka Adapter Capabilities
The Apache Kafka Adapter enables you
to create an integration in Oracle Integration that connects to an
Apache Kafka messaging system for the publishing and consumption of messages
from a Kafka topic.
This are some of the Apache Kafka Adapter benefits:
- Consumes messages from a Kafka topic and produces messages to a Kafka topic.
- Enables
you to browse the available metadata using the Adapter Endpoint Configuration
Wizard (that is, the topics and partitions to which messages are published and
consumed).
- Supports a
consumer group.
- Supports
headers.
- Supports
the following message structures:
·
XML schema
(XSD) and schema archive upload
·
Sample XML
·
Sample
JSON
- Supports
the following security policies:
·
Simple
Authentication and Security Layer Plain (SASL/PLAIN)
·
SASL Plain
over SSL, TLS, or Mutual TLS
More details on the documentation page: https://docs.oracle.com/en/cloud/paas/integration-cloud/apache-kafka-adapter/kafka-adapter-capabilities.html
How to set up everything?
I
installed Kafka on an Oracle Cloud VM running Oracle Linux. This was quite
straightforward. If you are new to Kafka, there are plenty of online available
resources for a step by step installation.
You
need Zookeeper and Apache Kafka – (Java is a prerequisite in the OS).
This
is a very simple configuration with 1 broker/node only, running on localhost.
From
an OIC standpoint you must satisfy the following prerequisites to create a
connection with the Apache Kafka Adapter:
- Know the host and port of the bootstrap server to use to connect to a list of Kafka brokers.
- For Security - username & password (unless you choose no security policy)
- For SASL over SSL, TLS, or Mutual TLS - have the required certificates.
I
add an extra pre-requisite which is the need for the OIC agent to be up and running.
I
installed the connectivity agent in the same machine as Kafka, but this can be
installed anywhere if they are in the same network.
How to create a connection?

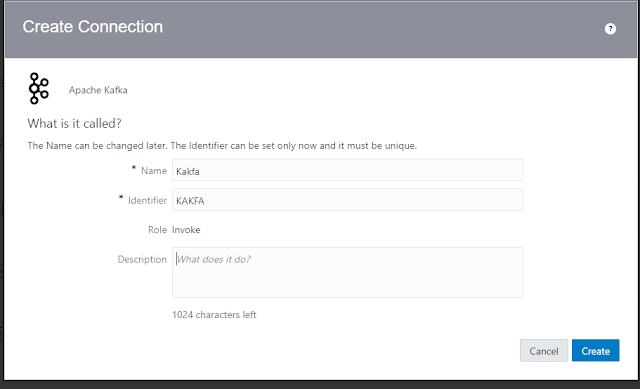
Choose
Apache Kafka as the desired adapter.
Name
your connection and provide an optional description.
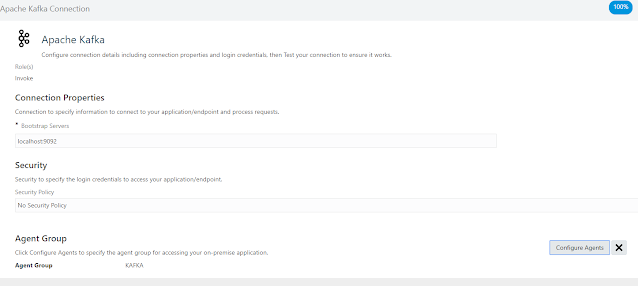
I used localhost:9092*
– this is because the actual connectivity is handled by the agent, so in
reality we are connecting to the Kafka server as if we were inside the machine
where it runs.
*9092 is the default Kafka port, but you can
verify the one you are using in <Kafka_Home>/config/server.properties
Security:
I choose no security policy but in a real-life
scenario this needs to be considered. More on this can be found in
the official documentation!
Agent Group:
Select the group to which your agent belongs.
Finally, test and verify the connection is successful.
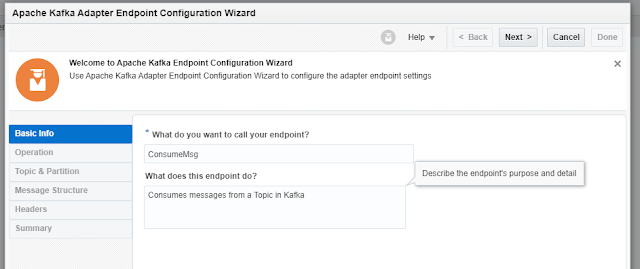
Create an Integration (Consume Messages)
So now, we can create a Scheduled Integration, and drag the Kafka Adapter from the Palette onto the Canvas.
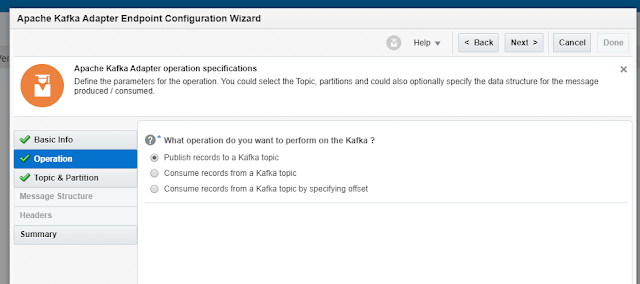
We can Produce or Consume Messages. Let’s look at Consume Messages.
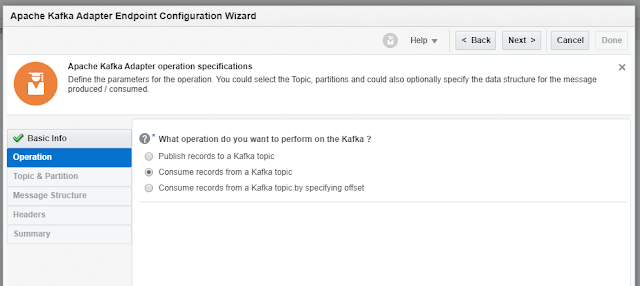
We have 2 options for consuming messages. With
or without offset
Part of the unique characteristic of Kafka (as
compared with JMS) is the client’s ability to select from where to read the
messages – offset reading.
If we choose offset reading, we need to specify
it, and the message consumption will start from there, as seen in the picture
below.
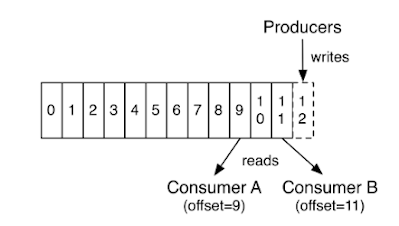
Picture from https://kafka.apache.org
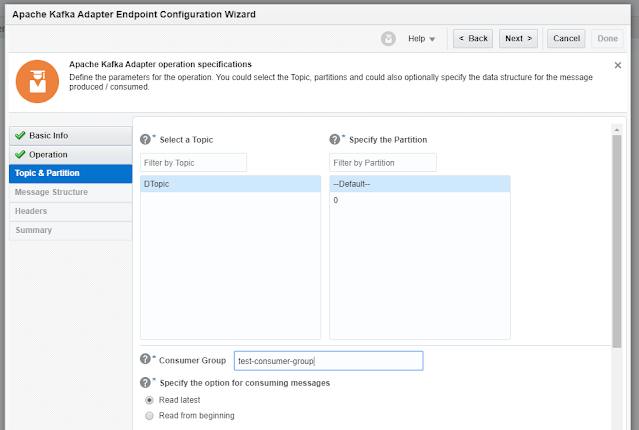
Select a Topic:
My Kafka server only has 1 Topic available –
DTopic.
Specify the Partition:
Kafka topics are divided into several partitions. Each one can be placed on a separate machine so
that multiple consumers can read from a topic at the same time. In our case there is only 1 partition – we can choose the one
to read from, or give Kafka the control to choose - If we do not select a
specific partition and use the Default selection, Kafka considers all available
partitions and decides which one to use
Consumer Group:
Kafka consumers are part of a consumer
group.
Those consumers will read from the same and
each consumer in the group will receive messages from different partitions in
the topic.
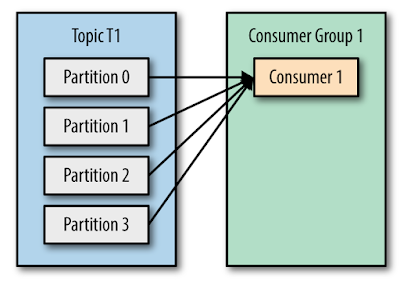
Picture from O’Reilly - Kafka: The Definitive Guide
The main way to scale data consumption
from a Kafka topic is by adding more consumers to a consumer group.

Picture from O’Reilly - Kafka: The Definitive Guide
I added this Integration to a consumer group
called: “ test-consumer-group” which only has 1 consumer.
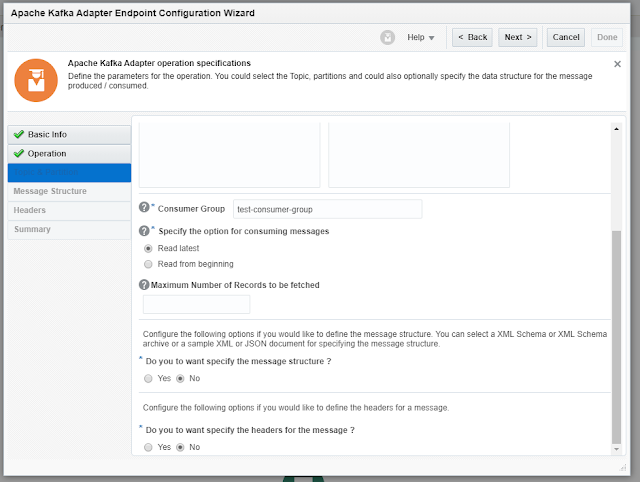
Specify Option for consuming messages:
Read latest:
Reads the latest messages starting at the time at which the integration was
activated.
Read from beginning: Select to read messages from the beginning.
Message structure & headers: I choose not to define the message structure, and the same
for headers.

This is what the Integration looks like. It
does not implement any specific use-case, it’s a pure showcase of the Kafka
adapter capabilities. Note that we are not mapping any data in the mapping
activity.
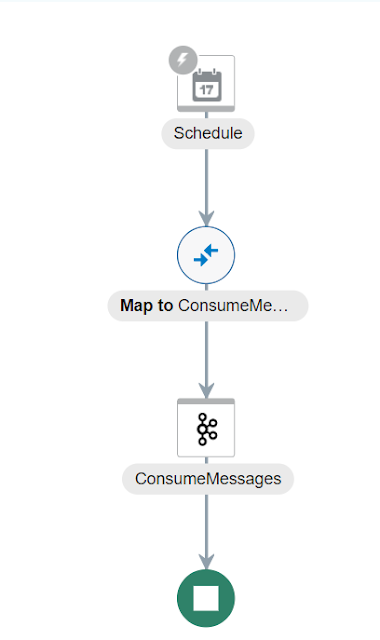
Now, going back to the Kafka server, we can produce some messages.
By using ./kafka-console-producer.sh script we can produce messages in the console.
>message for oic

When you run the Integration, that message is read by OIC as showed here in the Payload Activity Stream. The option to consume messages was - Read latest, otherwise we would get more in the output.
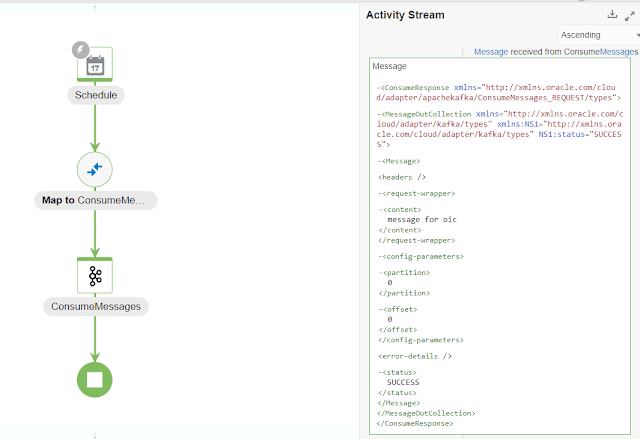
Easy and straightforward – which is the main benefit of Adapters, remove all Client complexity.
Create an Integration (Produce Messages)
Lastly, how to produce messages.
I have created a new topic - DTopic2 - to
receive the produce messages. Yes, I know, not very imaginative for naming
conventions!
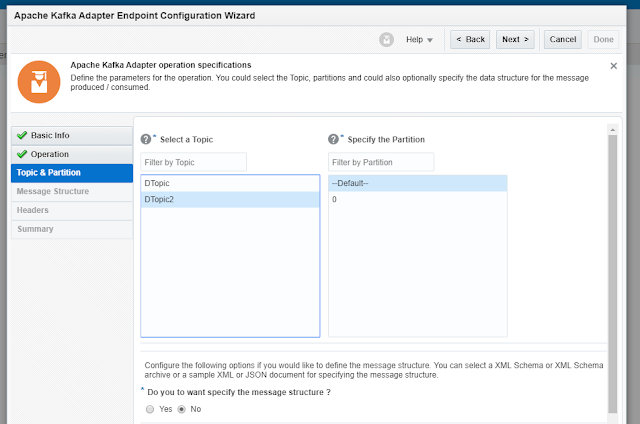
I select the desired topic, partition as default and do not want to specify message structure nor headers.

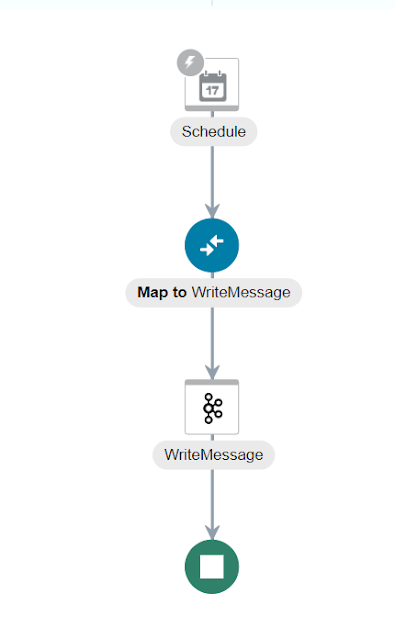
We need to map data, which translates to: What
is the data we want to produce in the topic.
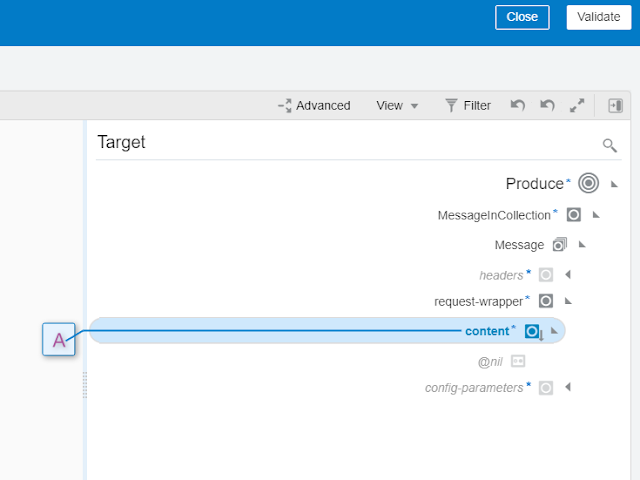
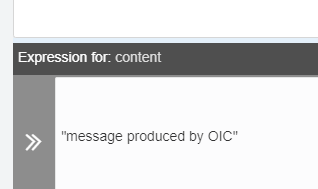
We hard-code the attribute Content with the following message:

I run the Integration, and we can see in the
Kafka console the message being consumed!
And if we go to the OIC monitoring we see the
same!
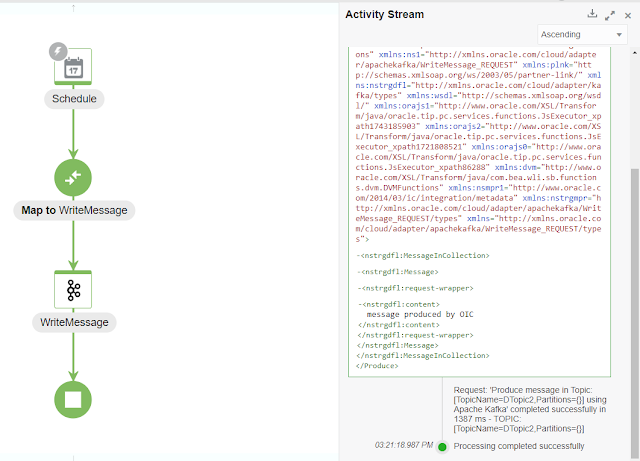
This shows how easy it is to create and manage
Kafka clients, both producer and consumer, from within OIC.
For more information please check: https://docs.oracle.com/en/cloud/paas/integration-cloud/apache-kafka-adapter
Sources:
https://kafka.apache.org
O’Reilly
Kafka: The Definitive Guide
Oracle
Documentation
Comments
Post a Comment